
Your first guide to MEAN Stack Development
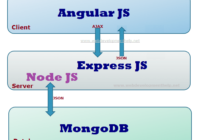
The fact that MEAN Stack uses JavaScript on all levels makes it extremely compelling which also makes it one of the most efficient and modern web development solutions. For those who are looking to explore more about web development, learning something about MEAN Stack development will be a good idea since it will be quite… Read More »






